Understanding and building a component selection process
This guide is designed for users who want to better understand the mechanics
of the component selection process and people who are considering customizing
their own decision tree or contributing to tedana code. We have tried to
make this accessible, but it is long. If you just want to better understand
what’s in the outputs from tedana start with
Classification output descriptions.
tedana involves transforming data into components, currently via ICA, and then
calculating metrics for each component. Each metric has one value per component that
is stored in a component_table dataframe. This structure is then passed to a
“decision tree” through which a series of binary choices categorize each component
as accepted or rejected. The time series for the rejected components are
regressed from the data in the final denoising step.
There are a couple of decision trees that are included by default in tedana but
users can also build their own. This might be useful if one of the default decision
trees needs to be slightly altered due to the nature of a specific data set, if one has
an idea for a new approach to multi-echo denoising, or if one wants to integrate
non-multi-echo metrics into a single decision tree.
Note
We use two terminologies interchangeably.
The whole process is called “component selection” and much of the code uses
variants of that phrase
(e.g. the ComponentSelector class,
selection_nodes for the functions used in selection).
We call the steps for how to classify components a “decision tree” since each
step in the selection process branches components into different intermediate
or final classifications.
Expected outputs after component selection
During processing, everything is stored in a
ComponentSelector called selector.
The elements of that object are then saved to multiple files.
The file key names are used below the full file names in the
Output filename descriptions.
General outputs from component selection
New columns in selector.component_table_ and the “ICA metrics tsv” file:
classification: While the decision table is running, there may also be intermediate classification labels, but the final labels are expected to be “accepted” or “rejected”. There will be a warning if other labels remain.
classification_tags: Human readable tags that explain why a classification was reached. Each component can have no tags (an empty string or n/a), one tag, or a comma separated list of tags. These tags may be useful parameters for visualizing and reviewing results
selector.cross_component_metrics_and “ICA cross component metrics json”:A dictionary of metrics that are each a single value calculated across components, for example, kappa and rho elbows. User or pre-defined scaling factors are also stored here. Any constant that is used in the component classification processes that isn’t pre-defined in the decision tree file should be saved here.
selector.component_status_table_and “ICA status table tsv”:A table where each column lists the classification status of each component after each node was run. Columns are only added for runs where component statuses can change. This is useful for understanding the classification path of each component through the decision tree
selector.treeand “ICA decision tree json”:A copy of the inputted decision tree specification with an added “output” field for each node. The output field (see next section) contains information about what happened during execution. Of particular note, each output includes a list of the metrics used within the node, “node_label”, which is a (hopefully) human readable brief description of the node’s function and, for nodes where component classifications can change, “n_false” & “n_true” list who many components changed classifications. The inputted parameters include “if_true” and “if_false” which specify what changes for each component. These fields can be used to construct a visual flow chart or text-based summary of how classifications changed for each run.
selector.tree["used_metrics"]and a field in “ICA decision tree json”:A list of the metrics that were used in the decision tree. Everything in
used_metricsshould be in eithernecessary_metricsorgenerated_metricsIf a used metric isn’t in either, a warning message will appear. This is a useful check that makes sure every metric used was pre-specified.selector.tree["classification_tags"]and a field in “ICA decision tree json”:A list of the pre-specified classification tags that could be used in a decision tree. Any reporting interface should use this field so that all possible tags are listed even if a given tag is not used by any component by the end of the selection process.
Outputs of each decision tree step
“ICA decision tree json” includes all the information from the specified decision tree for each “node” or function call. For each node, there is an “outputs” subfield with information from when the tree was executed. Each outputs field includes:
- decision_node_idx
The decision tree functions are run as part of an ordered list. This is the positional index (the location of the function in the list), starting with index 0.
- used_metrics
A list of the metrics used in a node of the decision tree
- used_cross_component_metrics
A list of cross component metrics used in the node of a decision tree
- node_label
A brief label for what happens in this node that can be used in a decision tree summary table or flow chart.
- n_true, n_false
For decision tree (dec) functions, the number of components that were classified as true or false, respectively, in this decision tree step.
- calc_cross_comp_metrics
For calculation (calc) functions, cross component metrics that were calculated in this function. When this is included, each of those metrics and the calculated values are also distinct keys in ‘outputs’. While the cross component metrics table does not include where each component was calculated, that information is stored here.
- added_component_table_metrics
It is possible to add a new metric to the component table during the selection process. This is useful if a metric is to be calculated on a subset of components based on what happened during previous steps in the selection process. This is not recommended, but, since it was done as part of the original decision tree process used in the meica and tedana_orig, it is possible.
Decision trees distributed with tedana
Two decision trees are distributed with tedana.
These trees are documented in Included Decision Trees.
It might be useful to look at these trees while reading how to develop a custom
decision tree.
Defining a custom decision tree
Decision trees are stored in json files. The default trees are stored as part of the tedana code repository in resources/decision_trees. The minimal tree, minimal.json, is a good example highlighting the structure and steps in a tree. It may be helpful to look at that tree while reading this section. meica.json replicates the decision tree used in MEICA version 2.5, the predecessor to tedana. It is more complex, but also highlights additional possible functionality in decision trees.
A user can specify another decision tree and link to the tree location when tedana is
executed with the --tree option. The format is flexible to allow for future
innovations, but be advised that this also allows you to create something with
non-ideal results for the current code. Some criteria will result in an error if
violated, but more will just give a warning. If you are designing or editing a new
tree, look carefully at the warnings.
A decision tree can include two types of nodes or functions.
All functions are currently in selection_nodes.
A decision function will use existing metrics and potentially change the classification of the components based on those metrics. By convention, all these functions begin with “dec”.
A calculation function will take existing metrics and calculate a value across components to be used for classification, for example the kappa and rho elbows. By convention, all these functions begin with “calc”.
Nothing prevents a function from both calculating new cross component values and applying those values in a decision step, but following this convention should hopefully make decision tree specifications easier to follow and results easier to interpret.
General information fields
There are several fields with general information. Some of these store general information that’s useful for reporting results and others store information that is used to check whether results are plausible & can help avoid mistakes.
- tree_id
A descriptive name for the tree that will be logged.
- info
A brief description of the tree for info logging
- report
A narrative description of the tree that could be used in report logging. This should include any citations, which must be included in the references BibTeX file.
- necessary_metrics
A list of the necessary metrics in the component table that will be used by the tree. This field defines what metrics will be calculated on each ICA component. If a metric doesn’t exist then this will raise an error instead of executing a tree. If a necessary metric isn’t used, there will be a warning.
- generated_metrics
An optional initial field. It lists metrics that are to be calculated as part of the decision tree’s execution. This is used similarly to necessary_metrics except, since the decision tree starts before these metrics exist, it won’t raise an error when these metrics are not found. One might want to calculate a new metric if the metric uses only a subset of the components based on previous classifications. This does make interpretation of results more confusing, but, since this functionality is part of the tedana_orig and meica decision trees, it is included.
- intermediate_classifications
A list of intermediate classifications (i.e. “provisionalaccept”, “provisionalreject”). It is very important to pre-specify these because the code will make sure only the default classifications (“accepted” “rejected” “unclassified”) and intermediate classifications are used in a tree. This prevents someone from accidentially losing a component due to a spelling error or other minor variation in a classification label.
- classification_tags
A list of acceptable classification tags (i.e. “Likely BOLD”, “Unlikely BOLD”, “Low variance”). This will both be used to make sure only these tags are used in the tree and allow programs that interact with the results to see all potential tags in one place. Note: “Likely BOLD” is a required tag. If tedana is run and none of the components include the “Likely BOLD” tag, then ICA will be repeated with a different seed and then the selection process will repeat.
External regressor configuration
external_regressor_config is an optional field. If this field is specified, then
additional metrics will be calculated that include F, 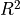 , and p values for the fit
of external regressors to each component time series.
The p value might be useful for defining a statistically significant fit,
while can assess whether the regressors model a meaningful amount of variance.
For example, even if nuisance regressors, like head motion, significantly fit an ICA component
time series, do not reject if they only model 5% of the total variance of that component.
, and p values for the fit
of external regressors to each component time series.
The p value might be useful for defining a statistically significant fit,
while can assess whether the regressors model a meaningful amount of variance.
For example, even if nuisance regressors, like head motion, significantly fit an ICA component
time series, do not reject if they only model 5% of the total variance of that component.
Users will need to specify the
external regressors using the --external option.
--external takes a TSV file in which each column has a header label and is the length
of the fMRI time series.
This functionality can be used to integrate non-multi-echo decision criteria,
such as correlations to head motion, CSF, or respiration time series.
These added metrics can then be used in decision tree steps just like any other metric.
Two demonstration trees that apply this functionality are in resources/decision_trees.
demo_external_regressors_single_model.json demonstrates the simplest application
of external regressors and demo_external_regressors_motion_task_models.json
highlights the full range of functionality.
This is an example TSV file with column labels that work with both of these trees.
Both these trees are based on minimal.json.
While these might be good decision trees to use as is,
they are both called “demo” because they demonstrate what is possible,
but the utility of these specific decision trees have not yet been validated.
external_regressor_config is a list of dictionaries.
Each dictionary defines statistical tests to apply to a group of
regressors specified in --external.
demo_external_regressors_single_model.json includes a single dictionary
that specifies fitting all supplied regressors to a single nuisance model that is
used to reject components.
demo_external_regressors_motion_task_models includes one dictionary for
a nuisance model to reject components and one for a task model to retain more
task-correlated signal. For the nuisance model, columns with specific header names
are also fit to partial models for motion and CSF regressors that are used to label
why components were rejected.
(i.e. Component X was rejected because it fit to head motion regressors.)
Each dictionary in external_regressor_config must include the following sub-fields:
- “regress_ID”
A descriptive name for the external regressors that will be logged. Will be used in the
selector.component_table_labels describing the outputs of the statistical tests. For example, if this field isnuisancethen component table column labels will include:Fstat nuisance model,R2stat nuisance model, andpval nuisance model.
- “info”
A brief description of the external regressors for info logging.
- “report”
A narrative description of how the external regressors are used that will be used in report logging. This should include any citations, which must be included in the references BibTeX file.
- “detrend”
“true” or “false” to specify whether to include detrending regressors when fitting the external regressors to the ICA component time series. If “true”, it will specify the number of detrending time regressors to include based on the length of the time series. If “false”, it will just include an intercept regressor to remove the mean. This can also be a integer that defines the number of regressors to include. Can also be an integer specifying the number of detrending regressors.
- “statistic”
The statistical test to use for fitting the external regressors to the ICA component time series. Currently, the only valid option is “F” for fitting using a linear model with an F statistic.
- “regressors”
A list of strings or regular expressions to specify the columns in the external regressor file to use in the model. Regular expressions begin with
^For example,["^.*$"]would mean use all regressors in the file, while["^mot_.*$"]would mean use all regressors with labels beginging withmot_.["mot_x", "mot_y_", "mot_z"]would be use regressors with those specific labels. Capitalization is ignored. Note: When tedana is run, regular expressions are replaced with the named regressors. The outputted decision tree will specify what was used and might be useful for validation.
An optional field is “partial_models”.
This is a dictionary where each element is a descriptor and column specification is similar to
regressors. For example, "partial_models": {"Motion": ["^mot_.*$"], "CSF": ["^csf.*$"]}
specifies two partial models for motion and CSF time series, where the columns in
the external regressor tsv begin with either mot_ or csf.
When this field is used, statistics will be calculated for the full model with all regressors
and each specified partial model. This can be used to potentially reject components that fit
any combination of nuisance regressors and also note which components fit head motion regressors.
If this option is included, there would be added columns in selector.component_table_, such as
Fstat nuisance Motion partial model, pval nuisance Motion partial model, and
R2stat nuisance Motion partial model
Nodes in the decision tree
The “nodes” field is an ordered list of elements where each element defines a node in the decision tree. Each node contains the information to call a function.
All trees should start with a “manual_classification” node that should set all component classifications to “unclassified” and have “clear_classification_tags” set to true. There might be special cases where someone might want to violate these rules, but depending what else happens in preceding code, other functions will expect both of these columns to exist. This manual_classification step will make sure those columns are created and initialized.
Every possible path through the tree should result in each component being classified as ‘accepted’ or ‘rejected’ by the time the tree is completed.
There are several key fields for each node:
“functionname”: The exact function name in
selection_nodesthat will be called.“parameters”: Specifications of all required parameters for the function in functionname
“kwargs”: Specifications for optional parameters for the function in functionname
The only parameter that is used in all functions is decide_comps, which is used to
identify, based on their classifications, the components a function should be applied
to. It can be a single classification, or a comma separated string of classifications.
In addition to the intermediate and default (“accepted”, “rejected”, “unclassified”)
component classifications, this can be “all” for functions that should be applied to
all components regardless of their classifications.
Most decision functions also include if_true and if_false, which specify how to change
the classification of each component based on whether a decision criterion is true
or false. In addition to the default and intermediate classification options, this can
also be “nochange”
(e.g., for components where a>b is true, “reject”, and for components where a>b is false, “nochange”).
The optional parameters tag_if_true and tag_if_false
define the classification tags to be assigned to components.
Currently, the only exceptions are manual_classify and dec_classification_doesnt_exist,
which use new_classification to designate the new component classification and
tag (optional) to designate which classification tag to apply.
There are several optional parameters (to include within “kwargs”) in every decision tree function:
custom_node_label: A brief label for what happens in this node that can be used in a decision tree summary table or flow chart. If custom_node_label is not not defined, then each function has default descriptive text.log_extra_info: Text for each function call is automatically placed in the logger output with the info label. These might be useful to give a narrative explanation of why a step was parameterized a certain way.only_used_metrics: If true, this function will only return the names of the component table metrics that will be used when this function is fully run. This can be used to identify all used metrics before running the decision tree.
"_comments" can be used to add a longer explanation about what a node is doing.
This will not be logged anywhere except in the tree, but may be useful to help explain the
purpose of a given node.
Key parts of selection functions
There are several expectations for selection functions that are necessary for them to
properly execute.
In selection_nodes,
manual_classify(),
dec_left_op_right(),
and calc_kappa_elbow()
are good examples for how to meet these expectations.
Create a dictionary called “outputs” that includes key fields that should be recorded.
The following line should be at the end of each function to retain the output info:
selector.nodes[selector.current_node_idx_]["outputs"] = outputs
Additional fields can be used to log function-specific information, but the following fields are common and may be used by other parts of the code:
“decision_node_idx” (required): the ordered index for the current function in the decision tree.
“node_label” (required): A decriptive label for what happens in the node.
“n_true” & “n_false” (required for decision functions): For decision functions, the number of components labeled true or false within the function call.
“used_metrics” (required if a function uses metrics): The list of metrics used in the function. This can be hard coded, defined by input parameters, or empty.
“used_cross_component_metrics” (required if a function uses cross component metrics): A list of cross component metrics used in the function. This can be hard coded, defined by input parameters, or empty.
“calc_cross_comp_metrics” (required for calculation functions): A list of cross component metrics calculated within the function. The key-value pair for each calculated metric is also included in “outputs”
Before any data are touched in the function, there should be an
if only_used_metrics: clause that returns used_metrics for the function
call. This will be useful to gather all metrics a tree will use without requiring a
specific dataset.
Existing functions define function_name_idx = f"Step {selector.current_node_idx_}: [text of function_name].
This is used in logging and is cleaner to initialize near the top of each function.
Each function has code that creates a default node label in outputs["node_label"].
The default node label may be used in decision tree visualization so it should be
relatively short. Within this section, if there is a user-provided custom_node_label,
that should be used instead.
Calculation nodes should check if the value they are calculating was already calculated and output a warning if the function overwrites an existing value
Code that adds the text log_extra_info into the output
log (if they are provided by the user)
After the above information is included,
all functions will call selectcomps2use(),
which returns the components with classifications included in decide_comps
and then runs confirm_metrics_exist(),
which is an added check to make sure the metrics
used by this function exist in the component table.
Nearly every function has a clause like:
if comps2use is None:
log_decision_tree_step(function_name_idx, comps2use, decide_comps=decide_comps)
outputs["n_true"] = 0
outputs["n_false"] = 0
else:
If there are no components with the classifications in decide_comps, this logs that
there’s nothing for the function to be run on, else continue.
For decision functions, the key variable is decision_boolean, which should be a pandas
dataframe column that is True or False for the components in decide_comps based on
the function’s criteria.
That column is an input to change_comptable_classifications(),
which will update the component_table classifications, update the classification history
in selector.component_status_table_, and update the component classification_tags. Components not
in decide_comps retain their existing classifications and tags.
change_comptable_classifications()
also returns and should assign values to
outputs["n_true"] and outputs["n_false"]. These log how many components were
identified as true or false within each function.
For calculation functions, the calculated values should be added as a value/key pair to
both selector.cross_component_metrics_ and outputs.
log_decision_tree_step()
puts the relevant info from the function call into the program’s output log.
Every function should end with:
selector.nodes[selector.current_node_idx_]["outputs"] = outputs
return selector
functionname.__doc__ = (functionname.__doc__.format(**DECISION_DOCS))
This makes sure the outputs from the function are saved in the class structure and the class structure is returned. The following line should include the function’s name and is used to make sure repeated variable names are compiled correctly for the API documentation.
If you have made it this far, congratulations!!! If you follow these steps, you’ll be able to impress your colleagues, friends, and family by designing your very own decision tree functions.